

Most restaurants don't fail because the food's bad. They fail because Tuesday's no-show cascade turns into Thursday's inventory crisis, which becomes Saturday's staffing nightmare, and by Sunday the whole operation is running on duct tape and prayers.
After watching countless restaurants try to scale past 100-150 covers per night, the pattern becomes obvious. The ones that make it have something the others don't—a single operational backbone that connects reservations to prep, prep to staffing, staffing to ordering. Not separate systems. One interconnected control loop where each piece triggers the next.
The restaurants that don't figure this out? They're the ones where the chef is texting the GM at 11pm about tomorrow's prep list while the floor manager is scheduling servers based on last Tuesday's weather and the owner is ordering produce based on what feels right. Eventually something breaks. Usually everything breaks.
Why restaurants hit the operational ceiling around 150 covers
There's this specific moment when restaurant operations shift from manageable chaos to actual breakdown. It happens around 150 covers per night, sometimes 200 if you're lucky. Below that threshold, a good manager can hold everything in their head. They know Sarah always calls out on Thursdays. They remember that table 23 tends to order extra appetizers. They sense when the walk-in's running low on romaine.
Cross that threshold and the human-brain-as-operating-system model collapses completely.
The reservation system shows 180 covers for Friday. Nobody tells prep that 40 of those are a corporate event ordering the prix fixe. Prep makes standard mise. The line gets hammered with unexpected volume on three dishes. Kitchen runs out of the special at 7:30. Servers start 86ing items. Guest experience tanks. Saturday's prep is now wrong because Friday burned through unexpected inventory. The cycle continues.
This isn't a communication problem. It's an architecture problem. The restaurant has no operational backbone—no unified system where a reservation automatically triggers prep adjustments, which trigger staffing changes, which trigger order modifications.
Mapping the control loop: reservation→prep→staffing→ordering
Loop 1: Reservation Intelligence
Eliminate operational bottlenecks effortlessly.
Dineoly helps you manage every reservation, order, and staff shift seamlessly.
- Unified reservation and order management
- Real-time staff scheduling
- Inventory and sales tracking
No credit card required
-
Booking comes in → System flags party size, time, historical ordering patterns
-
Reservation modifications → Automatically recalculates downstream impacts
-
Cancellation threshold crossed → Triggers staffing adjustment protocol
Loop 2: Prep Orchestration
-
Reservation data flows to prep lists → Adjusted for party composition, not just cover count
-
Special events flagged → Prep quantities modified for prix fixe or limited menus
-
Day-of changes → Real-time prep pivots based on actual reservations vs. projected
Loop 3: Staffing Calibration
-
Cover count + guest composition → Determines floor layout and station assignments
-
Prep requirements → Triggers kitchen staffing needs
-
Historical patterns → Adjusts for typical no-show rates by day/time
Loop 4: Inventory Procurement
-
Prep requirements aggregated → Creates ordering needs 48-72 hours out
-
Actual vs. projected usage → Adjusts next cycle's orders
-
Waste tracking → Feeds back into reservation acceptance thresholds
| Loop | Key points |
|---|---|
| Loop 1: Reservation Intelligence | Booking comes in → System flags party size, time, historical ordering patterns |
| Loop 2: Prep Orchestration | Reservation data flows to prep lists → Adjusted for party composition, not just cover count |
| Loop 3: Staffing Calibration | Cover count + guest composition → Determines floor layout and station assignments |
| Loop 4: Inventory Procurement | Prep requirements aggregated → Creates ordering needs 48-72 hours out |
Here's a simple visual of how those loops connect and feed back into each other.
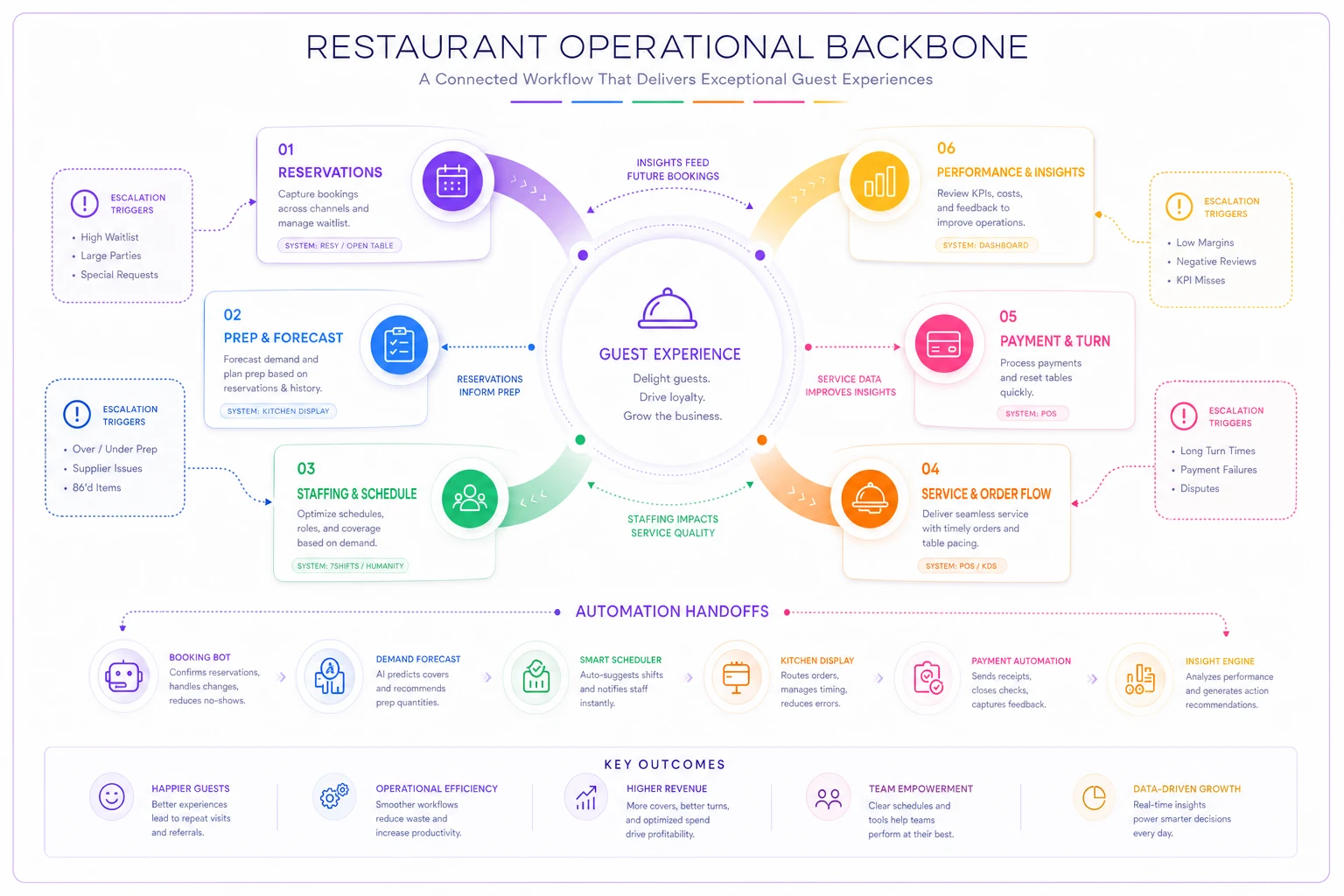
Each loop feeds the next. More importantly, each loop feeds back to adjust the others.
The handoff rules that prevent cascade failures
The difference between restaurants that scale and restaurants that implode comes down to handoff protocols. Not meetings. Not communication. Actual documented handoff rules that trigger automatically.
Reservation→Prep Handoff
-
Trigger
Daily at 3pm for next day's service
-
Data passed
Cover count by hour, party sizes, special requests, dietary restrictions aggregated
-
Escalation
If covers exceed 115% of normal → Prep lead notified immediately
-
Failure mode
If no handoff by 3:30pm → Backup protocol activates using 7-day average
Prep→Staffing Handoff
-
Trigger
Prep list finalized (usually 4pm day-before)
-
Data passed
Station requirements, expected ticket times, special prep needs
-
Escalation
If prep exceeds standard by 25% → Additional hands scheduled
-
Failure mode
If prep incomplete → Floor manager runs reduced menu protocol
Staffing→Ordering Handoff
-
Trigger
Schedule locked (48 hours before service)
-
Data passed
Projected covers based on staffing capacity, not reservations
-
Escalation
If staffing below minimum → Ordering reduced to prevent waste
-
Failure mode
If schedule changes <24 hours → Emergency order protocol activates
Make the 3pm reservation→prep handoff non-negotiable in the shift checklist so it doesn't rely on memory.
These aren't suggestions. They're system rules. When the reservation system shows 200 covers for Saturday but you can only staff for 160, the ordering automatically adjusts. The prep list automatically adjusts. The reservation system stops accepting bookings for peak hours.
Escalation triggers: when to break the system
Every operational backbone needs circuit breakers—specific conditions where you intentionally break the normal flow to prevent larger failures.
Reservation Escalations
-
Party of 12+ books → Manager approval required, prep notified immediately
-
Same-day reservation exceeds 20% of capacity → Auto-decline activates
-
Corporate event books → Triggers special event protocol, normal operations suspended
Prep Escalations
-
Prep time exceeds available hours → Menu reduction protocol activates
-
Key ingredient unavailable → Substitution matrix triggers
-
Prep cook calls out → Simplified prep list auto-generates
Staffing Escalations
-
Coverage drops below 80% → Service modification protocol (sections combined)
-
Key position unfilled → Role combination matrix activates
-
Multiple call-outs → Owner notified, reduced hours considered
Inventory Escalations
-
Stock below 2-day minimum → Emergency order triggered
-
Delivery failure → Backup supplier protocol activates
-
Storage capacity exceeded → Donation protocol triggers to prevent waste
The key: these escalations are predetermined. Not "we'll figure it out when it happens." When it happens, the protocol already exists.
Real failure-mode playbooks from actual operations
Scenario 1: The Thursday Night Reservation Bomb
-
A 150-seat restaurant gets a last-minute 40-person booking for Thursday at 7pm. Their normal Thursday runs about 100 covers total. Without an operational backbone, here's the cascade:
-
Hostess accepts the booking (commission incentive)
-
Kitchen finds out Thursday afternoon during lineup
-
No additional prep was done Wednesday
-
Can't call in extra cooks on short notice
-
Kitchen crashes at 7
45 when the party's mains fire
-
Regular guests wait 45+ minutes for food
-
Friday prep is now behind because Thursday ran late
-
Weekend service compromised
With the backbone in place:
-
System flags the 40-person booking as exceeding threshold
-
Auto-alert to kitchen manager Wednesday at 3pm
-
Prep list adjusts Wednesday evening
-
Thursday AM prep cook called in for 4 hours additional
-
Staffing system shows coverage gap, triggers "on-call" list
-
Orders placed Wednesday night for Friday delivery of depleted items
-
Thursday service runs normally, just busier
Scenario 2: The Saturday Supply Chain Failure
-
Your seafood delivery doesn't show up Saturday morning. You're expecting 180 covers, heavily promoted the weekend special (pan-seared scallops), and it's 8am.
-
Without backbone
-
Chef scrambles to find replacement
-
Calls three suppliers, finds scallops at 40% markup
-
Sends prep cook to pick up, loses 2 hours labor
-
Forgets to tell servers about price adjustment
-
Margin tanks on 60+ orders
-
Monday's order is now wrong because inventory assumptions are off
With backbone:
-
Delivery failure triggered at 7am (expected by 6
30)
-
Backup supplier protocol activates
-
Pre-negotiated backup pricing applies (15% markup max)
-
Server tablets update with "market price" notation
-
Reservation system notified to flag special as "limited availability"
-
Inventory system adjusts for emergency purchase
-
Monday order automatically compensates
Scenario 3: The Prep Cook Walkout
-
Tuesday afternoon, your main prep cook quits mid-shift. Walks out at 2pm with Wednesday's prep half done. You've got 160 on the books for Wednesday.
-
Without backbone
-
Sous chef stays until midnight finishing prep
-
Wednesday prep starts late
-
Lunch service compromised
-
Dinner prep rushed
-
Quality issues cascade through weekend
With backbone:
-
Walkout triggers "prep emergency" protocol at 2
15pm
-
Simplified prep matrix activates (reduces menu by 20%)
-
Server system updated with limited menu for Wednesday
-
Staffing system alerts all qualified prep cooks
-
Ordering system delays Thursday delivery to reduce waste
-
GM contacts guests with reservations about menu modifications
These real scenarios show how predefined protocols and automated handoffs prevent small shocks from becoming system-wide failures.
Building measurement loops that actually matter
Most restaurants measure the wrong things. They track food cost percentage while ignoring that their reservation-to-prep connection wastes 3% margin every single night. They monitor labor cost while missing that poor handoffs create 2 hours of unnecessary overtime daily.
The operational backbone needs different metrics:
Connection Metrics
-
Reservation-to-prep accuracy
How often does actual cover count match prep quantities?
-
Prep-to-service alignment
Are we running out of items or over-prepping?
-
Staff-to-demand ratio
Are we over/understaffed relative to actual (not projected) covers?
-
Order-to-usage variance
How much are we ordering vs. actually using?
Handoff Metrics
-
Handoff completion rate
What percentage happen on time?
-
Escalation frequency
How often do we need to break normal protocol?
-
Cascade failures
When one system fails, how many others are affected?
-
Recovery time
How quickly do we return to normal after a failure?
System Health Metrics
-
Loop cycle time
How long from reservation to prep to staff to order?
-
Adjustment frequency
How often are we making manual overrides?
-
Waste correlation
Does waste increase when handoffs fail?
-
Guest impact
Do online reviews mention operational issues?
Track these weekly. Not monthly. Weekly. Because operational problems compound fast in restaurants.
The technology layer (without the complexity)
Most restaurants think they need seven different systems talking to each other. They don't. They need one backbone that connects the pieces they already have.
The modern approach uses operational software that acts as connective tissue:
-
Pulls reservation data from your existing booking system
-
Pushes prep requirements to kitchen display systems
-
Integrates with scheduling software for staffing triggers
-
Connects to ordering platforms for inventory management
The AI automation component handles the intelligence layer—understanding patterns, predicting needs, flagging anomalies. It's not replacing your managers. It's giving them superhuman ability to see connections across the operation. When Tuesday's weather pattern looks similar to that Tuesday three weeks ago when you had 30% no-shows, the system adjusts Wednesday's prep automatically.
This isn't about replacing human judgment. It's about freeing humans from mechanical connection tasks so they can focus on hospitality, quality, and the guest experience.
Starting implementation: the 30-day backbone build
Don't try to build the entire backbone at once. Start with the most painful connection and expand from there.
Week 1-2: Map Your Current State
-
Document every handoff that happens (or should happen)
-
Identify where information gets lost
-
Count how many times someone says "nobody told me"
-
Track every time you run out of something or over-prep
Week 2-3: Build One Connection
-
Pick your biggest pain point (usually reservation→prep)
-
Create simple handoff rules
-
Document escalation triggers
-
Test with manual processes first
Week 3-4: Add Measurement
-
Track success rate of your one connection
-
Document failures and why they happened
-
Adjust rules based on actual operations
-
Begin connecting the next loop
Week 4+: Expand and Automate
-
Add the next connection
-
Start introducing technology where manual processes prove stable
-
Build measurement dashboards
-
Train team on escalation protocols
The restaurants that survive the next decade won't be the ones with the best food or the coolest atmosphere. They'll be the ones that build operational backbones strong enough to handle whatever chaos the world throws at them.
Your reservation system, prep lists, staffing schedules, and inventory orders all contain pieces of the same puzzle. The backbone connects them. Once those connections exist, you stop fighting fires and start preventing them.
The best part? Once the backbone is in place, scaling from 150 covers to 300 doesn't require heroics. It just requires following the system. The loops trigger, the handoffs happen, the escalations activate when needed. The restaurant runs itself while you focus on what actually matters—creating experiences that bring guests back.
That's the difference between restaurants that scale and restaurants that struggle. Not better recipes or fancier décor. Better operational architecture. A real backbone that connects every decision to every other decision, automatically, reliably, every single service.
The restaurants that survive the next decade won't be the ones with the best food or the coolest atmosphere. They'll be the ones that build operational backbones strong enough to handle whatever chaos the world throws at them.
Your reservation system, prep lists, staffing schedules, and inventory orders all contain pieces of the same puzzle. The backbone connects them. Once those connections exist, you stop fighting fires and start preventing them.
The best part? Once the backbone is in place, scaling from 150 covers to 300 doesn't require heroics. It just requires following the system. The loops trigger, the handoffs happen, the escalations activate when needed. The restaurant runs itself while you focus on what actually matters—creating experiences that bring guests back.
That's the difference between restaurants that scale and restaurants that struggle. Not better recipes or fancier décor. Better operational architecture. A real backbone that connects every decision to every other decision, automatically, reliably, every single service.
Ready to elevate your restaurant operations?
Join 2,000+ restaurants using Dineoly to enhance efficiency, increase table turnover, and delight diners.